Web Archive – czym jest?
Web Archive, czyli Internet Archive, to organizacja non-profit, która rozpoczęła swoją działalność już w 1996 r. od archiwizacji dopiero co zyskującego popularność internetu. Dzięki temu każdy użytkownik może całkowicie za darmo przejrzeć większość stron internetowych i to, jak zmieniały się one w czasie. Niestety, nie możesz uzyskać informacji na temat każdej witryny, która kiedykolwiek istniała w Internecie. W większości przypadków jednak Web Archive umożliwia przeglądanie poprzednich wersji serwisu nawet w kilkuminutowych odstępach. Wszystko zależy tak naprawdę od częstotliwości zmian na stronie i jej wielkości.

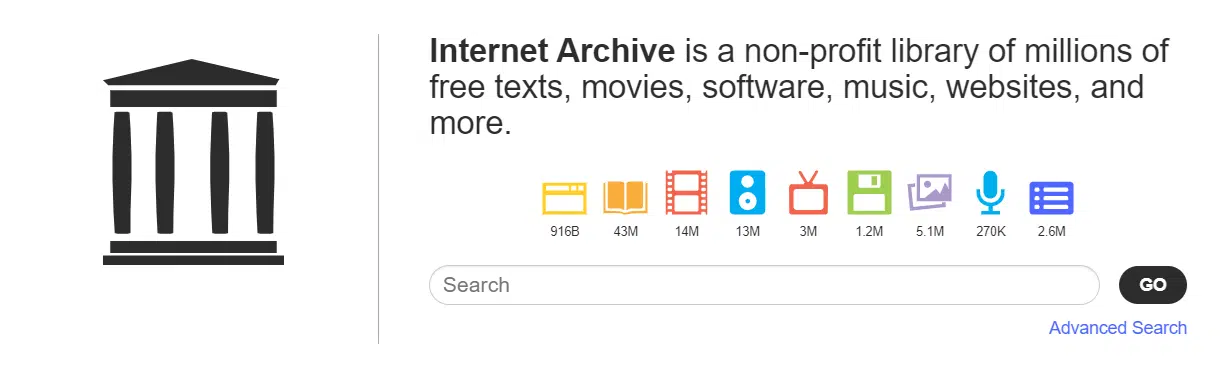
Misją Internet Archive było zapisanie treści cyfrowych, dużo bardziej ulotnych niż te wydawane w formie gazet. W 2000 roku zostało stworzone także archiwum wiadomości telewizyjnych, aby ułatwić naukowcom i opinii publicznej cytowanie oraz odnoszenie się do tych treści. Jednym z głównym celów organizacji pozostaje także pomoc osobom, które mogą mieć trudności z nawiązaniem interakcji z fizyczną książką, dlatego większość treści jest dostępna także dla osób niepełnosprawnych. Obecnie w archiwum można znaleźć ogromne liczby stron internetowych (916 mld), książek i tekstów (43 mln), nagrań audio (13 mln), filmów (14 mln), obrazów (5,1 mln) czy programów komputerowych (1,2 mln). Dzięki dostępowi do tak dużej ilości zasobów Web Archive stało się potężnym zbiorem kopii, które mają za zadanie chronić treści internetowe i walczyć z ich ulotnością.
Jak działa Web Archive Machine?
Web Machine czy też Wayback Machine to jedno z narzędzi stworzonych przez organizację Internet Archive, które umożliwia przeglądanie archiwalnych stron internetowych i ich wcześniejszych wersji. Dzięki temu użytkownik może prześledzić, jak dana strona zmieniała się w czasie i jakie modyfikacje zostały na niej wprowadzone. Dane zbierane są dzięki crawlowaniu stron przez roboty, skanowaniu ich i zapisywaniu w formie snapshotów. Crawlery działają według określonego harmonogramu, w regularnych odstępach czasu. Częstotliwość archiwizacji każdej strony jest inna – zależy od popularności witryny i wprowadzania na niej zmian.
Jak korzystać z Web Archive do przeglądania archiwalnych stron internetowych?
Narzędzie Web Archive Machine jest banalnie proste w użytkowaniu i przede wszystkim darmowe. Dodatkowo nie jest konieczne zakładanie konta. Aby zacząć z niego korzystać, wejdź na stronę web.archive.org i wpisz adres URL domeny, której historię chcesz przeanalizować.
W rezultacie otrzymasz oś czasu, na której możesz wybrać konkretną datę i godzinę, aby dowiedzieć się, jak wtedy wyglądała dana strona.
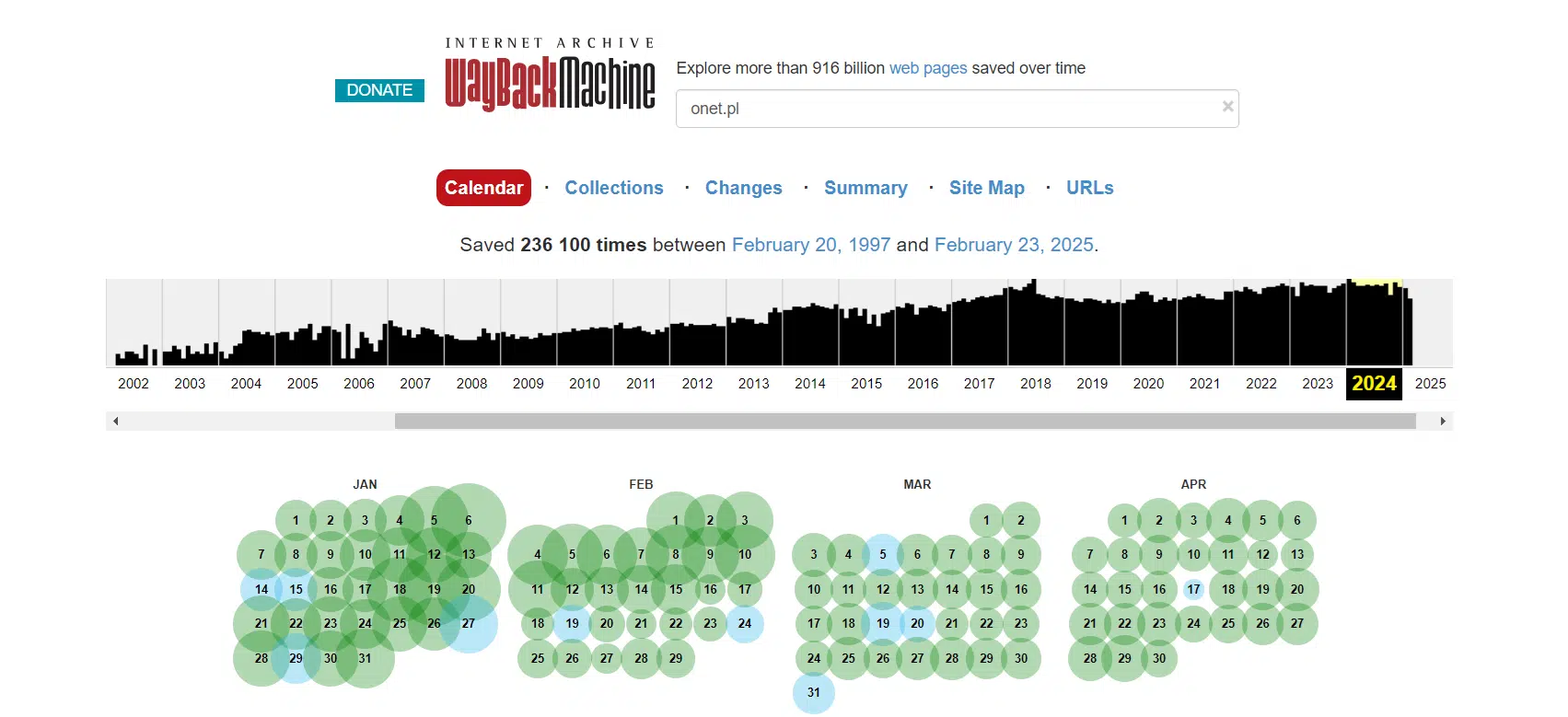
W ten sposób jesteś w stanie uzyskać podgląd strony w perspektywie nawet kilku czy kilkunastu lat. Dzięki archiwizowaniu witryn opublikowanych w internecie możesz sprawdzić także te, które zostały już usunięte.
Przykładowo strona onet.pl została zapisana przez roboty skanujące ponad 230 tys. razy od początku istnienia usługi Web Archive. Odpowiednio poruszając się po narzędziu, możesz sprawdzić i przeanalizować każdy z tych widoków. Najpierw wybierz rok, który Cię interesuje, potem miesiąc, dzień i godzinę. Nie każda strona będzie miała tak dużo zapisanych snapshotów. Im większa strona i im więcej zmian jest na niej dokonywanych, tym częściej roboty skanujące będą ją odwiedzać.
Zastosowanie Web Archive Machine w działaniach związanych z SEO
Narzędzie Web Archive ma wiele zastosowań, które możesz wykorzystać w optymalizacji swojej strony pod kątem SEO. Przede wszystkim w szybki sposób możesz:
- Odtworzyć utraconą zawartość – w przypadku, kiedy z różnych powodów utracisz treści na stronie, dzięki Archive Web jesteś w stanie dotrzeć do nich i je odtworzyć (włącznie np. z linkowaniem wewnętrznym). Może to być przypadkowe usunięcie elementu strony bez wykonania wcześniejszej kopii zapasowej lub problemy wynikające z niezależnych od Ciebie problemów technicznych z serwerem.
- Sprawdzić, jak zmieniała się strona w czasie – jest to ważne, kiedy chcesz się dowiedzieć, jak wyglądała struktura Twojej strony lub strony Twojego klienta, jakie treści były na niej publikowane, jak zmieniały się jej funkcjonalności i jak te zmiany wpływały na widoczność witryny w wyszukiwarce. W połączeniu z innymi narzędziami analitycznymi pozwoli Ci to na dokładną weryfikację, jakie rezultaty przyniosły modyfikacje dokonywane na stronie.
- Przeanalizować działania konkurencji – poprzez sprawdzenie, jakie zmiany na stronie wprowadza Twoja konkurencja, możesz dostosowywać swoją strategię marketingową tak, aby zawsze być krok przed nią. Dowiesz się, jak ewoluował wygląd strony, jakie treści były na niej publikowane oraz czym chciała się wyróżnić na tle innych.
- Poznać trendy, które występowały w różnych okresach czasowych – dzięki nim możesz poznać charakterystykę Twojej branży, aby jeszcze trafniej kierować swoją strategię do grupy docelowej.
- Zweryfikować historię domeny – to zastosowanie przyda Ci się w momencie, kiedy chcesz kupić wygasłą domenę. Dzięki Web Archive sprawdzisz, jak wyglądała poprzednia wersja strony oraz jakie treści były na niej publikowane. Ułatwi Ci to też zweryfikowanie, czy nie miała wcześniej kary nałożonej przez Google.
Praktyczne przykłady użycia Web Archive w badaniach i analizach
Znaczenie Web Archive w badaniach i analizach nieustannie wzrasta, zwłaszcza że internet wciąż dynamicznie się zmienia. Mogą korzystać z niego badacze historii i kultury, bibliotekarze, prawnicy czy marketerzy. Praktycznych zastosowań tego narzędzia jest wiele.
Jednym z najoczywistszych przykładów jego użycia jest badanie historii internetu i zmian, które miały miejsce w ogólnej przestrzeni cyfrowej. Dzięki temu można poznać obowiązujące w danym okresie trendy w projektowaniu stron internetowych, to, jak UX zmieniało się na stronach w perspektywie czasu i co budziło największe zainteresowanie odbiorców. W ten sposób można przeanalizować, jak ewoluowało podejście do odbiorcy, jak wyglądała komunikacja z użytkownikami i które działania sprawdzały się najlepiej w docieraniu do konkretnej grupy docelowej.

Należy zwrócić także uwagę na wykorzystanie Web Archive w analizowaniu konkurencji na przestrzeni lat. Badanie wyglądu i struktury strony konkurenta pozwala na poznanie jego strategii marketingowej oraz zrozumienie, jakie kampanie marketingowe były przez niego prowadzone. Wyciągając odpowiednie wnioski, można zdobyć informacje na temat tego, które treści były najwartościowsze dla użytkownika, a w przypadku sklepów internetowych – które produkty czy usługi najlepiej się sprzedawały. Zebranie tych danych pozwala na poznanie panujących trendów i ulepszenie swojej strategii, tak aby wyprzedzić konkurencję.
Sieć nieustannie się zmienia, zmieniają się trendy, a co za tym idzie – wygląd stron internetowych i oczekiwania odbiorców. Chcą oni w jak najszybszy sposób wyszukiwać interesujące ich treści i otrzymywać jak najbardziej satysfakcjonujące odpowiedzi. Web Archive odgrywa ogromną rolę w ochronie dziedzictwa cyfrowego. Dzięki niemu można zachować stare wersje stron i dowiedzieć się, jak wyglądały początki internetu oraz jak ewoluował on w czasie. Jest to niezwykle ważne dla nauki, aby nie utracić części kultury i historii. Dzięki inicjatywom takim jak Internet Archive w przyszłości badacze zajmujący się rozwojem technologii będą mogli analizować ewolucję interfejsów, technologii i trendów.
Korzyści i ograniczenia korzystania z Web Archive
Podsumowując, Web Archive jest niezastąpionym narzędziem w sytuacji, kiedy potrzebujesz dotrzeć do strony czy źródła, które już nie istnieje lub zmieniło swoją formę. Dzięki niemu możliwe jest zachowanie historii cyfrowej tych stron i wrócenie do niej w przyszłości. Jest to niezwykle istotne dla badaczy, historyków, archiwistów czy nawet specjalistów od marketingu. To archiwum internetu można śmiało nazwać narzędziem badawczym. Naukowcy mogą z niego korzystać, prowadząc analizy pod kątem historycznym czy społecznym, aby wiedzieć, jak w różnych okresach zmieniały się trendy i strategie.
Web Archive przydaje się także właścicielom stron internetowych, aby analizować działania konkurencji. Wyciągając odpowiednie wnioski z dostarczonych danych, można dowiedzieć się, jaką strategię marketingową stosuje, jakie produkty oferowała i jakie zmiany wprowadziła na przestrzeni miesięcy czy lat. Warto też wdrożyć to narzędzie przy przeprowadzaniu audytu SEO strony, zwłaszcza gdy chodzi o zakup nowej domeny, której historię chcesz zweryfikować i na tej podstawie opracować strategię poprawy widoczności – w czym niezwykle pomocne może okazać się profesjonalne pozycjonowanie lokalne.
Web Archive ma także zastosowanie jako dowody cyfrowe, z których prawnicy mogą korzystać w sprawach o naruszenie praw autorskich czy zniesławienie. Przede wszystkim jednak ma ogromne znaczenie dla dziedzictwa kulturowego – pomaga zachować pamięć o tym, co było istotne dla społeczeństwa w danym czasie.
Ale Web Archive to niestety nie tylko szereg korzyści i możliwości, które oferuje. Korzystając z niego, możesz napotkać się także na wiele ograniczeń, które prawdopodobnie utrudnią prowadzone przez Ciebie badania i analizy. Przede wszystkim są to:
- Niekompletność danych – narzędzie nie archiwizuje wszystkich stron internetowych, które są dostępne w internecie, ani wszystkich ich wersji. Możesz się spotkać z sytuacją, że wpisywany przez Ciebie adres URL nie wskaże żadnych wyników lub pokaże bardzo mało i nie uzyskasz interesujących Cię informacji. Niektóre strony specjalnie blokują możliwość odwiedzania ich przez roboty archiwizujące, a co za tym idzie – nie będą one dostępne w archiwum.
- Problemy z renderowaniem archiwalnych wersji stron – niektóre elementy strony, np. multimedia, miewają problem z wczytywaniem się w archiwum. Może to utrudnić przeglądanie zapisanej strony i zrozumienie jej całościowego przekazu.
- Brak aktualizacji w czasie rzeczywistym – strony archiwizowane przez Web Archive nie będą od razu widoczne w najnowszej wersji. Po opublikowaniu aktualizacji trzeba czekać, aż roboty archiwizujące odwiedzą i zeskanują witrynę, aby znalazła się w archiwum stron internetowych.
Narzędzie Web Archive jest nieocenione, jeśli chodzi o możliwość dostępu do starych wersji stron internetowych, musisz jednak liczyć się z tym, że nie zawsze otrzymasz wszystkie dane, które chcesz wyszukać. Możesz wykorzystać to narzędzie na wiele sposobów i z pewnością przyda Ci się jego znajomość. Pomimo pewnych ograniczeń jest niezastąpionym źródłem informacji dla wielu specjalistów z różnych dziedzin.
