Crawl budget i znaczenie zarządzania budżetem indeksowania w SEO
Budżet indeksowania (ang. crawl budget) określa limit czasu oraz zasobów, jakie roboty indeksujące wyszukiwarki Google przeznaczają na przeszukanie, a następnie zaindeksowanie danej strony. Jest to zagadnienie szczególnie ważne w przypadku domen posiadających bardzo dużo podstron, czyli np. sklepów internetowych.
W celu wyznaczenia budżetu crawlowania Google wyodrębniło dwa czynniki: crawl rate limit, czyli limit prędkości crawlowania, oraz crawl demand, czyli popyt na crawlowanie. Crawl rate limit określa maksymalną liczbę żądań, które roboty wyszukiwarki są w stanie wykonać na stronie w określonym czasie, nie przeciążając przy tym serwera. Wartość crawl demand zależy od tego, jak często treści w Twojej witrynie są aktualizowane oraz na ile jest ona popularna. Czynnik ten można więc określić mianem zapotrzebowania wyszukiwarki na skanowanie kolejnych stron.
Budżet indeksowania jest jednym z najważniejszych czynników wpływających na indeksację stron, a co za tym idzie, na ich pozycjonowanie w wynikach wyszukiwania. Ponieważ Google ma ograniczone zasoby w zakresie skanowania i indeksacji, warto jest zarządzać budżetem indeksowania tak, żeby jak najlepiej go wykorzystać.
Jak działa Google i w jaki sposób zbiera dane? Proces crawlowania i indeksowania
Wyszukiwarka Google używa wielu zaawansowanych algorytmów pozwalających w sposób sprawny i zorganizowany skanować sieć oraz indeksować treści. Googlebot skanuje każdą domenę w celu analizy jej zawartości oraz struktury linków. Od budżetu crawlowania zależy, jak dokładnie strona będzie przeszukana przez bota w określonym czasie. Może się więc zdarzyć, że w przypadku witryn z dużą ilością treści przy jednocześnie niskim budżecie indeksowania nie wszystkie podstrony zostaną zaindeksowane.
Renderowanie treści a limit szybkości indeksowania vs zapotrzebowanie na indeksowanie
Celem googlebotów jest indeksowanie witryn bez obciążenia serwerów. Żeby to osiągnąć, obliczana jest maksymalna liczba jednoczesnych połączeń równoległych użytych do zeskanowania witryny, czyli limit wydajności indeksowania. Dodatkowo kalkulowane są opóźnienia między pobraniami.
Wysokość limitu szybkości indeksowania zależy od takich czynników jak stan indeksowania (to, jak szybko strona reaguje) oraz limity indeksowania (liczba komputerów, jakie Google wykorzystuje w danym czasie do procesu indeksacji stron).
Przy określaniu ilości czasu, jaki Google przeznacza na indeksowanie witryny, pod uwagę brana jest jej wielkość, to, jak często jest aktualizowana oraz jakie są jakość i trafność zamieszczonej na niej treści. Możemy wyróżnić trzy czynniki, które odgrywają dużą rolę w określeniu zapotrzebowania na indeksowanie:
- Domniemane zasoby – jeżeli nie wykluczysz części stron z indeksacji, Google będzie starał się zeskanować wszystkie podstrony Twojej domeny. W przypadku stron ze zduplikowaną treścią, niedziałających adresów lub podstron z nieistotnymi informacjami niejako „zjadasz” swój crawl budget, który w tym samym czasie mógłby zostać wykorzystany do zaindeksowania bardziej istotnych z Twojego punktu widzenia podstron.
- Popularność – jeżeli poszczególne strony Twojej witryny są często odwiedzane przez użytkowników, są też częściej indeksowane, żeby móc dostarczać im aktualne informacje.
- Brak aktualizacji – googleboty starają się indeksować strony wystarczająco często, by wykryć zmiany w obrębie danej podstrony.
Jak sprawdzić limit szybkości indeksowania? Analiza w Google Search Console
Limit indeksowania można zweryfikować w Google Search Console. W nowej wersji GSC narzędzie Statystyki indeksowania dostępne jest w zakładce Ustawienia, pod adresem: https://search.google.com/u/2/search-console/settings/crawl-stats.
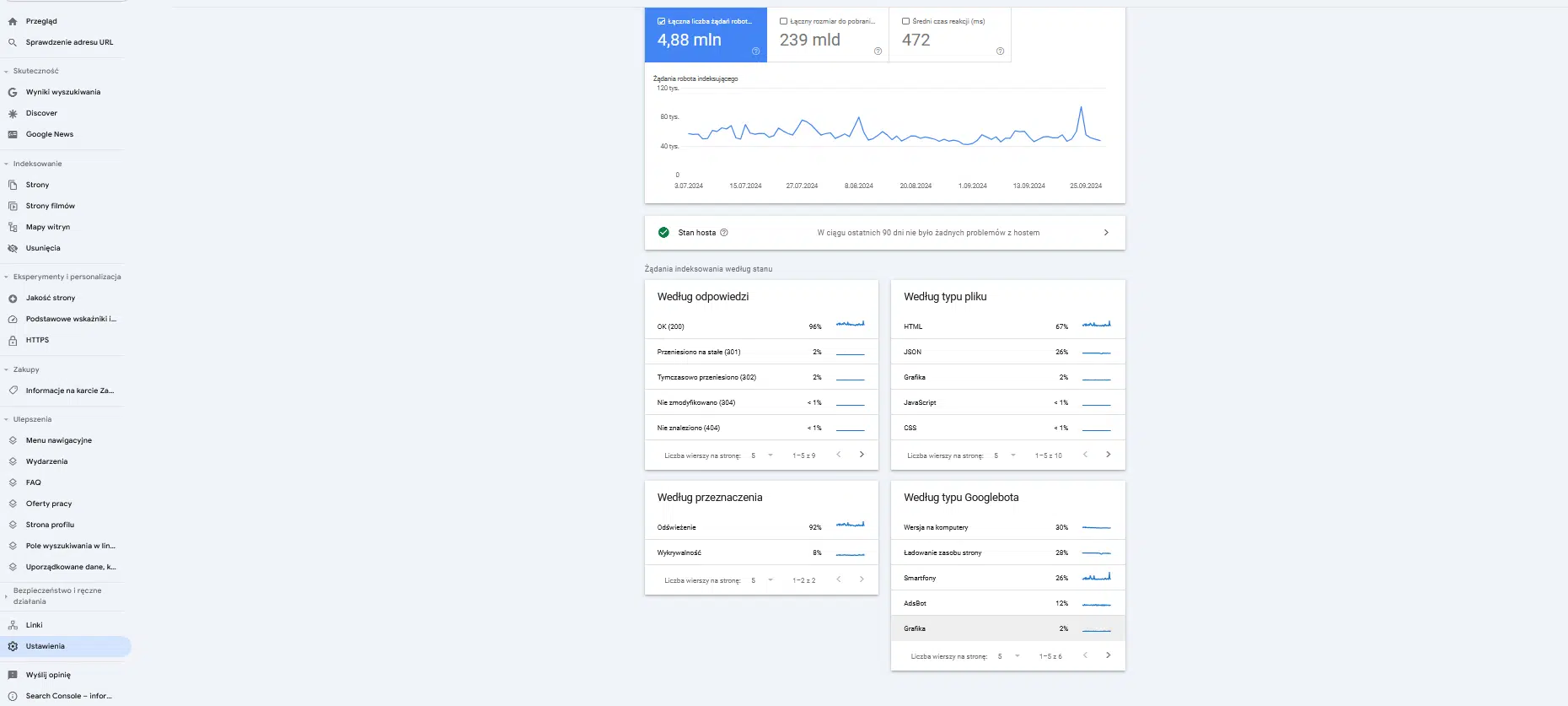
Raport ten prezentuje statystyki dotyczące indeksowania Twojej witryny przez Google w przeszłości. Zawiera takie informacje jak liczba wysłanych żądań, czas oraz treść odpowiedzi serwera lub ewentualne problemy z dostępnością.
Czynniki wpływające na budżet indeksowania
Wśród czynników wpływających na wysokość budżet crawlowania wymienić można szybkość ładowania treści (wolno ładujące się strony mogą obniżyć crawl rate) oraz linkowanie wewnętrzne (dobra struktura linków pozwala botom szybciej i wydajniej przeszukiwać stronę, co z kolei może zwiększyć crawl budget). Również bardzo popularne witryny mogą posiadać większy crawl demand.
Wydajność serwera i kody odpowiedzi serwera
To, na jakim serwerze (pod względem jakości) postawiona jest witryna, ma duże znaczenie, ponieważ słabe serwery uniemożliwiają wykorzystanie w pełni zasobów na indeksowanie. Dlatego przy wyborze hostingu pod uwagę powinna zostać wzięta wydajność serwera – SEO, mimo najlepszej nawet strategii, nie przyniesie oczekiwanych efektów, jeśli zaniedbasz ten aspekt. W przypadku dużej liczby odpowiedzi serwera z kodami błędów 404/410 zasoby goooglebota będą przeznaczane na sprawdzanie tych niedziałających stron, wskutek czego najbardziej wartościowe podstrony mogą nie zostać zaindeksowane.
Linkowanie wewnętrzne
Linkowanie wewnętrzne ma znaczenie dla lepszej nawigacji z perspektywy nie tylko użytkownika, ale również robotów, które przez takie linki przechodzą na inne podstrony. Co do zasady najważniejsze podstrony powinny być linkowane bezpośrednio ze strony głównej – zwiększa to szansę na ich indeksację, ponieważ strona główna witryny jest zazwyczaj stroną najczęściej odwiedzaną przez roboty.
Nawigacja fasetowa i blokady w pliku robots.txt
Nawigacja fasetowa to popularne w sklepach internetowych filtrowanie produktów. Umożliwia ona dopisanie wielu parametrów do jednego produktu, co po pierwsze prowadzi często do duplikacji treści, a po drugie – Google może dotrzeć do ogromnej liczby powstałych przez taką nawigację podstron, poświęcając całe zasoby na indeksowanie nie tych stron, na których Ci zależy. Z analizy logów serwera można wywnioskować, że Google traci na nie wiele czasu, a nie przynoszą nam one korzyści.
Na szczęście takie podstrony da się wykluczyć z procesu crawlowania. Podstrony będące rezultatami wyników wyszukiwania lub filtrów na stronie, a także inne strony niebiorące udziału w pozycjonowaniu witryny najlepiej zablokować w pliku robots.txt.
Duplikacja treści i thin content
Duplikacja treści to powtarzanie zawartości jednej podstrony na innej. W tym przypadku roboty Google zużywają zasoby na przeszukiwanie już zaindeksowanych stron. Warto tu pamiętać o tagach kanonicznych, czyli elementach kodu, które linkują do oryginalnej wersji serwisu, z pominięciem kopii.
Przez thin content z kolei rozumiemy treść niskiej jakości publikowaną na stronie. Zalicza się do tego treści, które zawierają wiele błędów merytorycznych czy też językowych lub nie wnoszą żadnej konkretnej wartości. Thin contentem jest również sytuacja, gdzie stosunek treści do kodu HTML jest bardzo niski. Google może ograniczyć indeksowanie zawartości takich stron, nawet jeśli mają one znaczenie (np. strony sklepów z produktami bez unikalnego opisu produktu).
Jak analizować i optymalizować crawl budget?
Nie każda witryna wymaga optymalizacji budżetu indeksowania. Google sugeruje, że co do zasady witryny posiadające mniej niż 1000 podstron nie powinny przejmować się tym, w jaki sposób wykorzystywane są na nich zasoby botów crawlujących. Warto jest jednak wdrażać zdrowe nawyki związane z optymalizacją, zwłaszcza na portalach, których zawartość podlega ciągłym zmianom (np. dodawane są regularnie nowe podstrony). Pozwoli to ograniczyć przebudowy struktury strony w przyszłości.
Jakie są charakterystyczne oznaki problemów z budżetem indeksowania?
Samo określenie, czy strona ma za niski crawl budget, jest trudne, ponieważ na indeksowanie stron ma wpływ wiele składowych. Zwykle jednak będziesz w stanie się zorientować, że Twoja witryna ma jakiś problem z budżetem indeksowania. Przede wszystkim poszukaj odpowiedzi na następujące pytania:
- Ile czasu zajmuje zaindeksowanie nowo opublikowanych treści lub podstron?
- Czy strona najpierw zostaje zaindeksowana, a później traci indeksację?
- Jak długo Google utrzymuje w indeksie nieaktualne adresy URL?
- Jak dużo czasu Google poświęca na podstrony bez żadnego ruchu?
Przydatne narzędzia do analizy budżetu indeksowania
Wśród przydatnych narzędzi do crawl budget management (oraz szerzej rozumianej analizy technicznej strony) wymienić trzeba Google Search Console, zewnętrzne roboty indeksujące takie jak Screaming Frog SEO Spider, narzędzia SEO do śledzenia widoczności, jak np. Senuto, czy też narzędzia do analizy linków zwrotnych, jak Ahrefs, Majestic.
Google Search Console – raporty pokrycia indeksu i statystyki indeksowania
W ramach analizy crawl budget Google Search Console prezentuje nam dwa główne raporty: Index Coverage (pokrycie indeksu) oraz Statystyki indeksowania.
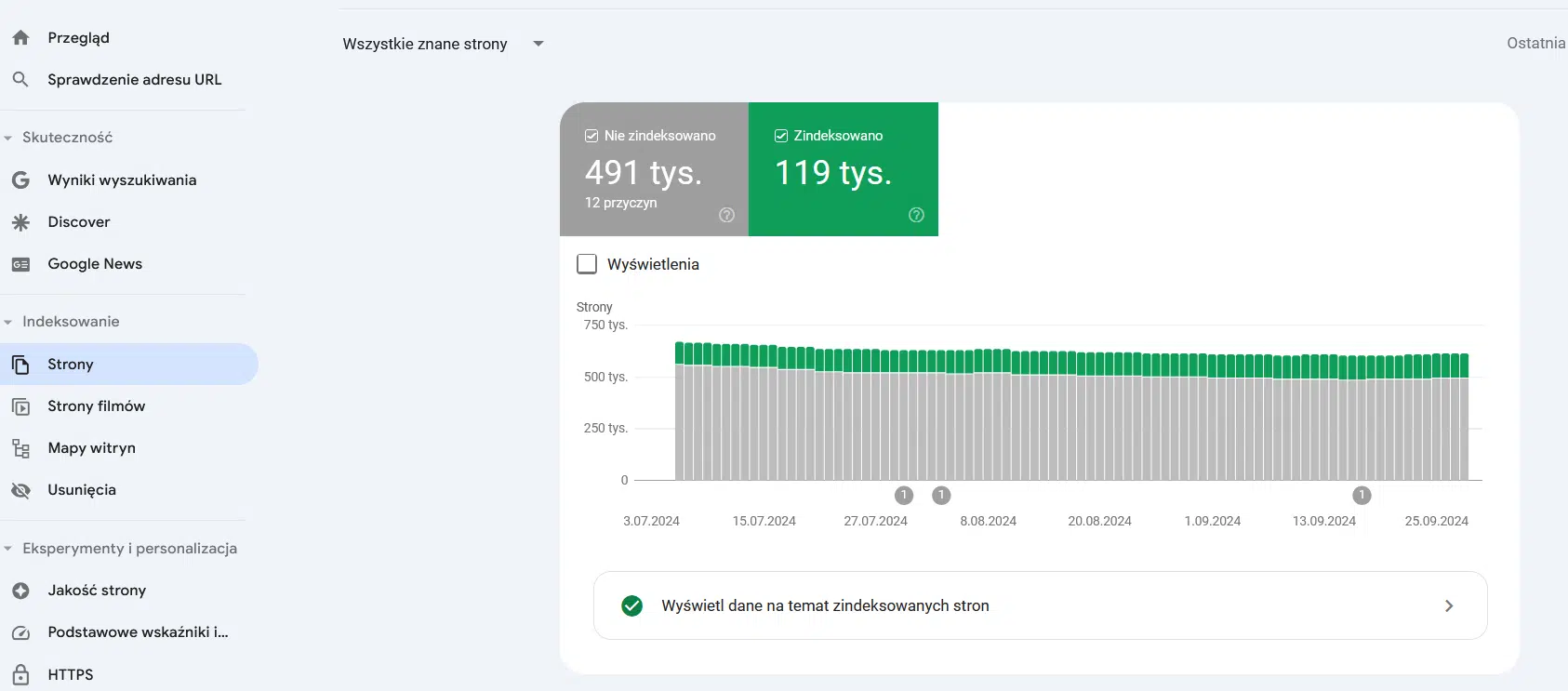
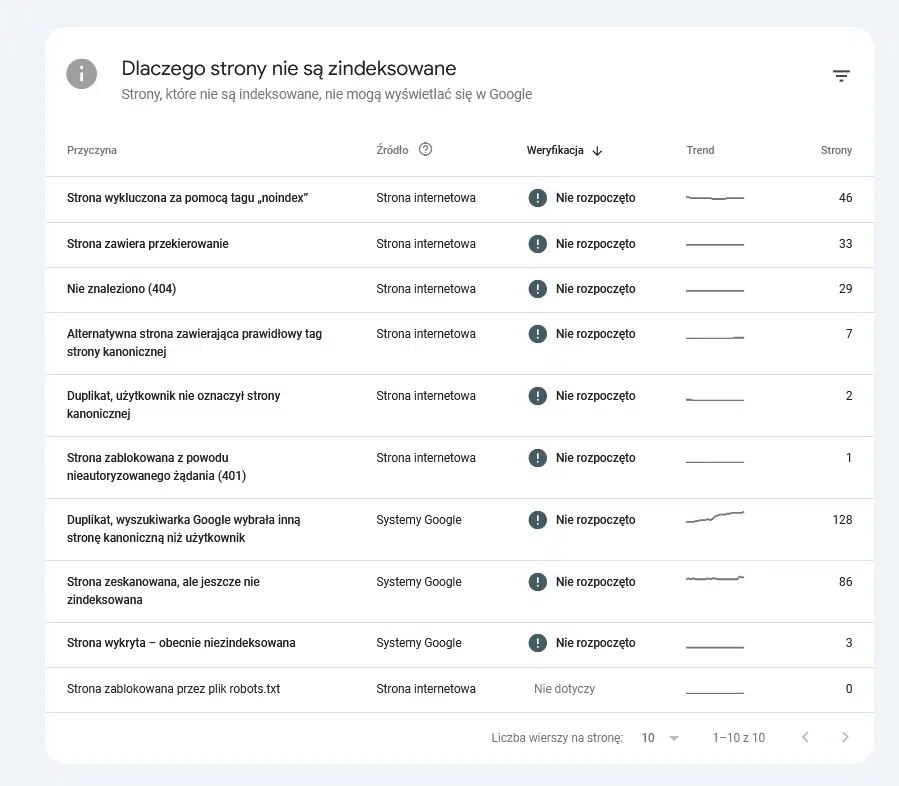
Raport Index Coverage jest bardzo obszerny, warto jednak skupić się na kilku danych dotyczących adresów, które zostały wykluczone z indeksowania:
- strona wykluczona za pomocą tagu „noindex”,
- strona zeskanowana, ale jeszcze niezindeksowana,
- strona wykryta, a obecnie niezindeksowana,
- duplikat, użytkownik nie oznaczył strony kanonicznej,
- duplikat, wyszukiwarka Google wybrała inną stronę kanoniczną niż użytkownik – pozorny błąd 404,
- duplikat, przesłany URL nie został oznaczony jako strona kanoniczna.
Raport Statystyki indeksowania prezentuje informacje dotyczące historii indeksowania Twojej witryny przez Google. Są to:
- łączna liczba żądań robota indeksującego,
- całkowity rozmiar pobierania,
- średni czas odpowiedzi,
- stan hosta,
- odpowiedzi na żądania robota indeksującego,
- typ pliku,
- cel indeksowania,
- typ Googlebota.
Zewnętrzne roboty indeksujące (Screaming Frog SEO Spider)
Screaming Frog SEO Spider jest jednym z najważniejszych narzędzi do analizy sposobu, w jaki boty crawlujące poruszają się po stronie. Dzięki niemu można sprawdzić, czy witryna jest poprawnie indeksowana (zwłaszcza najważniejsze podstrony). Warto tu wspomnieć o możliwości połączenia tego crawlera z danymi z GSC i GA.
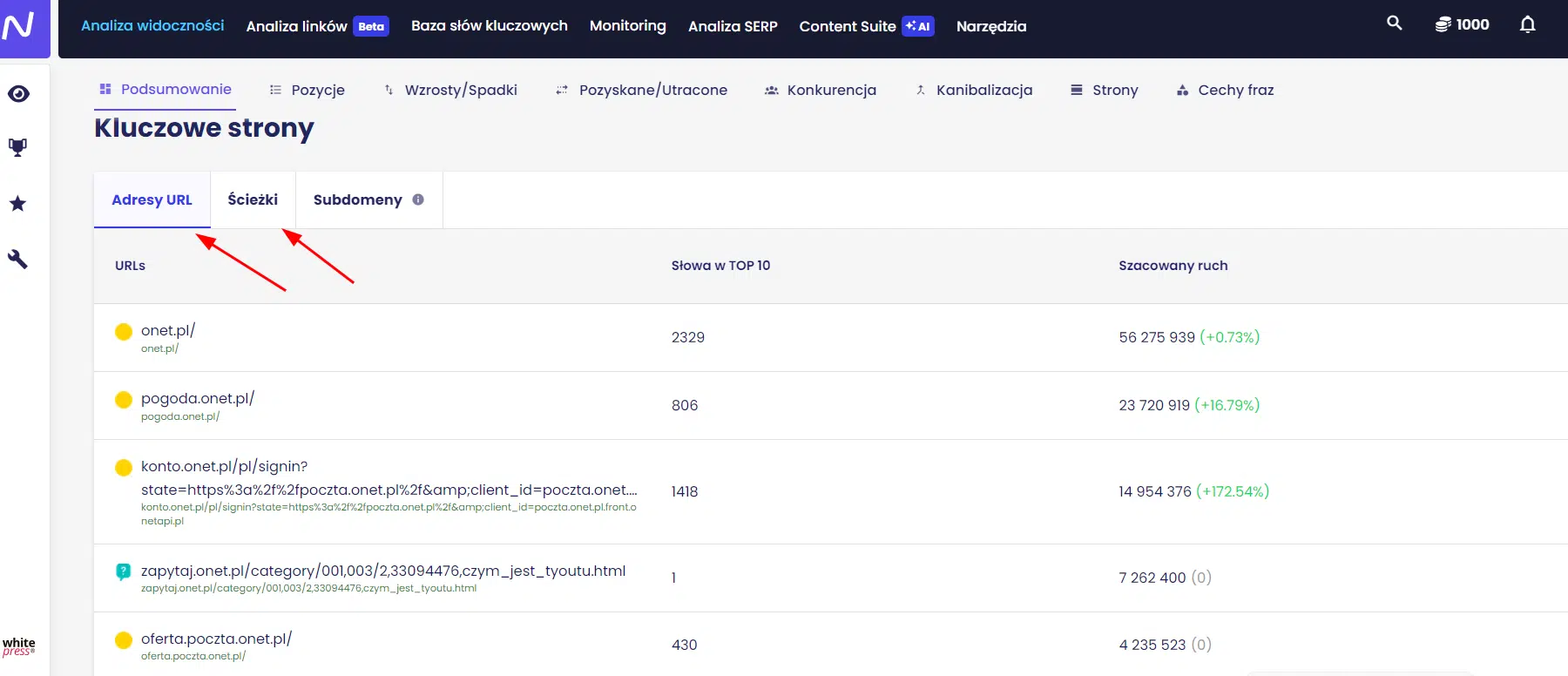
Narzędzia do śledzenia widoczności (Senuto)
Narzędzia do śledzenia widoczności takie jak Senuto są bardzo przydatne, ponieważ pomagają zidentyfikować podstrony mające wysokie pozycje na określone frazy z Google. W badaniu tego zagadnienia w Senuto pomocne są dwa raporty, dostępne w zakładce Sekcje w Analizie widoczności – są to Ścieżki oraz Adresy URL. Pozwalają one określić słowa kluczowe, na które witryna widoczna jest w top wyników wyszukiwania. Strony te powinny mieć potencjalnie większy crawl demand.
Narzędzia do analizy linków zwrotnych (Ahrefs, Majestic)
Duża liczba linków zwrotnych do wybranej podstrony jest okazją do optymalizacji budżetu indeksowania. Strony posiadające sporo wartościowych backlinków mają większe szanse na bycie crawlowanymi częściej. W narzędziu Ahrefs w celu ich zidentyfikowania mamy do dyspozycji raport Best by links.
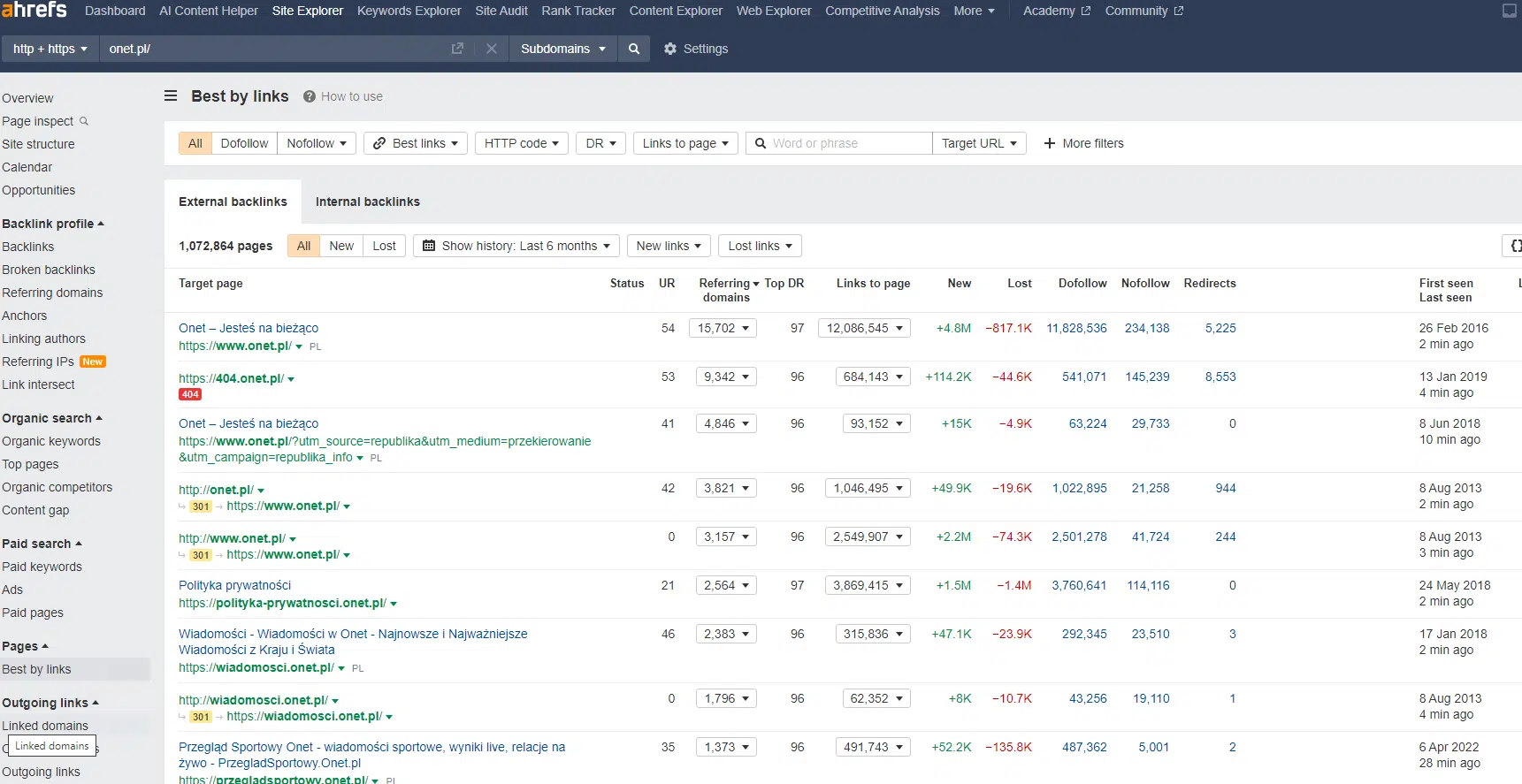
Narzędzia takie jak Ahrefs mają jednak pewną wadę – są płatne, a do tego dość drogie. Nie każdemu właścicielowi strony internetowej będzie się opłacało wykupienie abonamentu. Dlatego prace nad analizą i optymalizacją crawl budget można też zlecić zewnętrznym specjalistom, zaczynając od profesjonalnego audytu SEO.
Optymalizacja budżetu indeksowania – najlepsze praktyki i zalecenia. Jak zebrać i analizować dane w celu poprawy wydajności indeksowania?
Do podstawowych zaleceń dotyczących optymalizacji budżetu indeksowania możemy zaliczyć eliminację błędów 400, analizę tagów noindex, przegląd pliku robots.txt oraz sitemap.xml, analizę adresów URL bez tagów kanonicznych i usuwanie duplikatów treści, zbadanie filtrów i eliminację tych najmniej efektywnych z procesu indeksowania, a także poprawę architektury informacji, renderowania treści i ogólnej wydajności witryny. Poniżej w 10 punktach krótko omówię wymienione zagadnienia.
- Eliminacja błędów 404/410 – naprawa błędów i usunięcie przekierowań z linkowania wewnętrznego
Obecność adresów URL z kodem odpowiedzi 404 jest naturalnym zjawiskiem – w ten właśnie sposób są oznaczane usunięte albo niepoprawne adresy w witrynie. Warto jest je wyeliminować poprzez analizę przekierowań wewnętrznych oraz usunięcie błędów. W przeciwnym razie Google będzie rzadziej i krócej odwiedzać Twój serwis, uznając go za mniej wartościowy dla użytkowników.
- Usuwanie duplikatów treści – konsolidacja duplikatów i unikanie kanibalizacji słów kluczowych
Sprawdź, czy w strukturze witryny nie występują duplikaty oraz czy nie dochodzi do kanibalizacji słów kluczowych. Zjawisko to często występuje w przypadku sklepów internetowych, gdzie z uwagi na filtrowanie produktów powstają nowe strony z tą samą treścią.
- Analiza tagów noindex – minimalizacja udziału tagów noindex w strukturze strony
Zweryfikuj, czy Twoja strona ma wiele podstron z tagiem noindex. O ile takie strony – jak sama nazwa wskazuje – nie powinny być indeksowane, Google nadal może je odwiedzać, marnując zasoby. Być może nie wszystkie z nich są Ci rzeczywiście potrzebne? Postaraj się wyeliminować ze struktury serwisu jak najwięcej stron z tagiem noindex.
- Przegląd pliku robots.txt – sprawdzenie blokowanych struktur i usunięcie nieaktualnych dyrektyw
Należy dokładnie przejrzeć plik robots.txt. Warto sprawdzić, które z blokowanych adresów są mimo to crawlowane. Dobrze jest też usunąć nieaktualne reguły z pliku.
- Analiza adresów URL bez tagów kanonicznych – sprawdzenie wpływu tagów canonical na indeksowanie
Sprawdź, jak wiele adresów w obrębie witryny nie jest kanonicznych. Tag canonical jest bardzo często pomijany przez wyszukiwarkę, skutkiem czego np. parametry sortowania są nadal w indeksie.
- Filtry i ich mechanizmy – ograniczenie nieoptymalnych filtrów e-commerce
Filtrowanie listingów, zwłaszcza w e-commerce, prowadzi do powstania bardzo wielu nowych stron (zazwyczaj bez unikalnej treści), co często okazuje się bardzo zasobożerne dla budżetu indeksowania. Jak wspominałam wyżej, takie podstrony najlepiej wykluczyć z indeksowania w pliku robots.txt.
- Architektura informacji – ułatwienie indeksowania i linkowania wewnętrznego
Praca nad architekturą informacji zalicza się do najważniejszych elementów optymalizacji crawl budget. Według ogólnie przyjętej zasady najważniejsze biznesowo strony powinny być linkowane ze strony głównej lub sitewide.
- Renderowanie treści – upewnienie się, że Googlebot ma dostęp do treści JS/CSS
Renderowanie jest istotne w przypadku witryn, które linkowanie wewnętrzne opierają na zachowaniu użytkowników, głównie za pomocą plików cookies. Ponieważ Google nie zapisuje ciasteczek, a co za tym idzie, nie podlega personalizacji, nie widzi zawartości lub widzi to samo.
Dodatkowo częstym błędem jest blokowanie zawartości JS/CSS dla robotów Google. Przez to mogą pojawić się problemy z indeksacją stron.
- Core Web Vitals – optymalizacja wydajności
Core Web Vitals to zestaw wskaźników, które Google opracowało w celu oceny jakości i doświadczeń użytkowników w witrynach internetowych. Pod uwagę brane są tu trzy statystyki:
- Largest Contentful Paint – określa czas ładowania największego elementu na stronie,
- First Input Delay – określa czas między pierwszym interakcją użytkownika a reakcją strony,
- Cumulative Layout Shift – ocenia stabilność układu strony podczas ładowania.
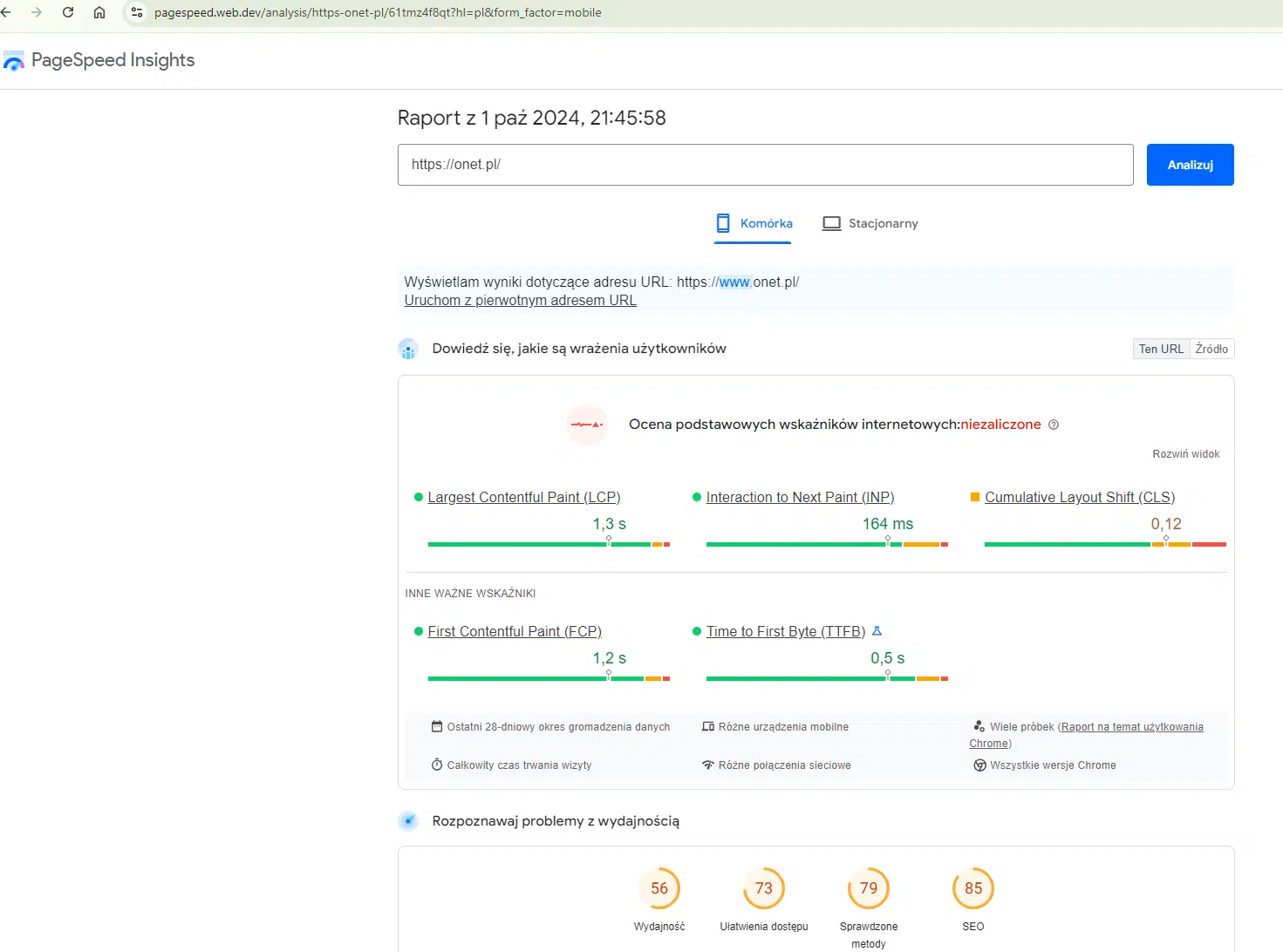
Ich optymalizacja przyczynia się do przyspieszenia ładowania strony, a co za tym idzie, zapewnia lepszy UX oraz poprawienie wydajności crawlowania.
- Sitemap.xml – sprawdzenie, czy plik działa poprawnie i zawiera kluczowe elementy
W celu potwierdzenia, że sitemapa działa poprawnie, warto jest zweryfikować w GSC składnię pliku, jego strukturę oraz poprawność najważniejszych elementów, a także dostępność mapy witryny i jej walidację. Opcjonalnie można sprawdzić plik w konsoli przeglądarki.
