Meta tagi noindex a follow i nofollow – różnice i stosowanie
Meta tag noindex oraz nagłówek odpowiedzi HTTP o tej samej dyrektywie stanowią podstawowy sposób kontrolowania indeksacji witryn przez wyszukiwarki internetowe. Wskazują robotom, aby nie uwzględniały w wynikach wyszukiwania oznaczonych w ten sposób stron internetowych. Z kolei follow oraz nofollow to meta tagi informujące roboty indeksujące o tym, jak traktować linki umieszczone na stronie. Atrybut nofollow komunikuje robotom, że linki oznaczone w ten sposób nie powinny być śledzone. Natomiast atrybut dofollow lub brak atrybutu oznacza, że roboty mają śledzić linki i przekazywać tzw. link juice. Wart odnotowania jest również fakt, iż atrybut nofollow może zostać umieszczony wraz z meta tagiem noindex w sekcji head, co jest sygnałem dla robotów, aby nie podążały za żadnymi linkami umieszczonymi na danej stronie internetowej.
Jakich podstron nie uwzględniać w indeksie domeny, żeby uniknąć marnowania zasobów crawlowania?
Aby płynnie przejść do zagadnienia związanego z podstronami, których lepiej unikać w indeksie domeny, warto skupić się na zagadnieniu crawl budgetu, który jest jednym z kluczowych pojęć bezpośrednio związanych z indeksowaniem. Crawl budget to ilość zasobów, które wyszukiwarka może przeznaczyć na indeksowanie treści na konkretnej stronie w danym czasie. Dla właścicieli aplikacji internetowych jest to istotne zagadnienie, ponieważ efektywne zarządzanie budżetem crawlowania może przynieść wymierne korzyści w postaci indeksacji wyłącznie pożądanych stron, co w konsekwencji będzie skutkowało lepszą widocznością w wynikach wyszukiwania oraz szybszym indeksowaniem. W związku z powyższym w celu optymalizacji tego procesu najlepiej jest zrezygnować z indeksowania zduplikowanych, alternatywnych oraz funkcyjnych stron, które nie wnoszą dla użytkowników żadnej wartości.
W przypadku sklepów internetowych istnieją konkretne rodzaje stron, których warto unikać w indeksie domeny. Należą do nich strony rejestracji i logowania, podobnie regulaminy oraz polityki prywatności, które – choć istotne dla działalności sklepu – nie prezentują istotnej wartości dla użytkowników.
W kontekście witryn produktowych, gdzie różnorodność wersji produktów może prowadzić do powielania treści, istotne jest wskazanie jednoznacznej strony kanonicznej. Dzięki temu roboty wyszukiwarek będą miały jasne wskazanie, który wariant produktu jest najważniejszy i powinien być uwzględniony w wynikach wyszukiwania.
Podobnie w przypadku stron z paginacją i filtrami warto wskazać stronę kanoniczną, która będzie prowadziła do podstawowej wersji strony, pozbawionej filtrów. Dzięki temu zabiegowi unikniesz problemów związanych z duplikacją treści oraz ułatwisz robotom wyszukiwarek interpretację struktury witryny.
Jak sprawdzić, czy Twoja strona jest w indeksie Google?
Status indeksacji w Google można sprawdzić na kilka sposobów. Pierwszym, a zarazem najprostszym rozwiązaniem jest użycie jednego z tzw. operatorów zaawansowanego wyszukiwania site wraz z adresem URL, którego obecność w indeksie chcesz sprawdzić – np. site:https://semhouse.com/pl/konsultacje-seo. Po wprowadzeniu takiej kwerendy w sytuacji, gdy adres został uwzględniony w indeksie Google, wyszukiwarka zwróci poniższy rezultat:
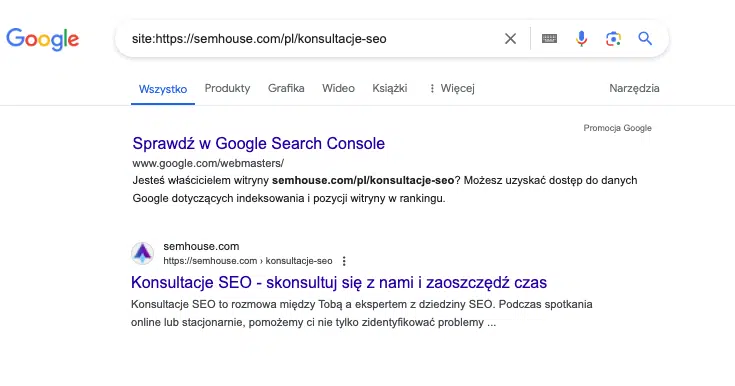
W przypadku braku strony w indeksie wynikiem wyszukiwania będzie następujący efekt:
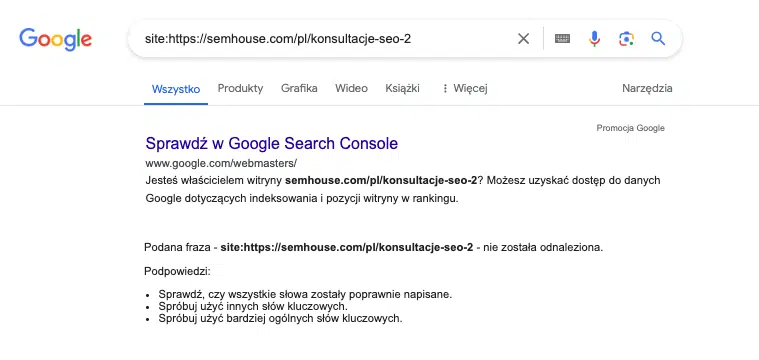
Kolejnym rozwiązaniem, które pozwoli na kompleksową, a zarazem kompletną analizę stron uwzględnionych w indeksie, jest skorzystanie z oficjalnego narzędzia dostarczanego przez Google, czyli Google Search Console. Narzędzie to pozwala sprawdzić listę wszystkich adresów URL, które zostały zaindeksowane w ramach danej domeny.
Sprawdzenie zaindeksowanych stron jest możliwe po zalogowaniu się do narzędzia oraz przejściu do sekcji Indeksowanie, a następnie Strony, gdzie ukaże Ci się wykres przedstawiający stosunek stron zaindeksowanych do tych, które nie zostały uwzględnione w indeksie.
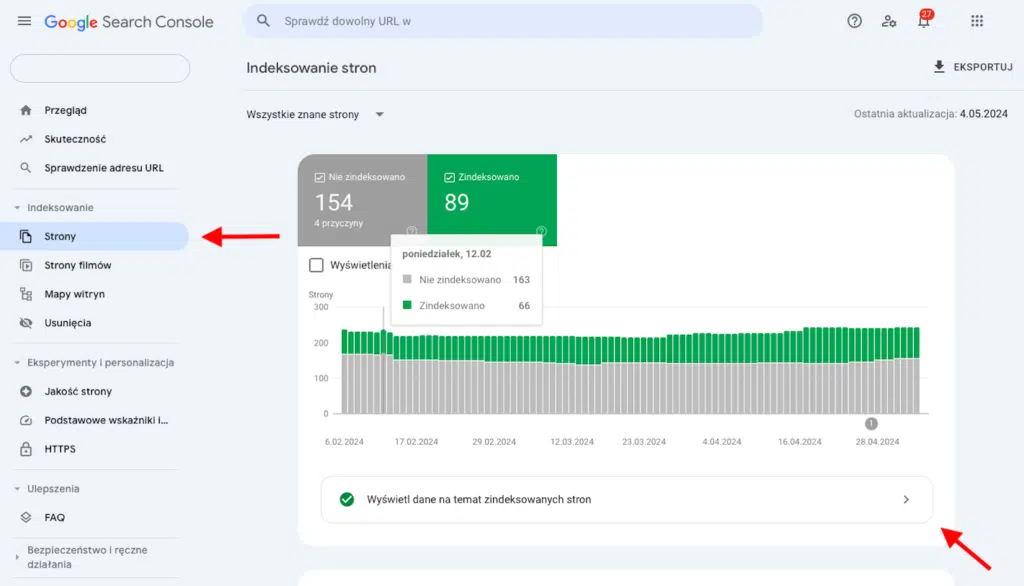
W kolejnym kroku należy kliknąć Wyświetl dane na temat zindeksowanych stron, gdzie zobaczysz wszystkie zaindeksowane adresy URL w czasie oraz pobierzesz je wraz z datą ostatniego indeksowania.
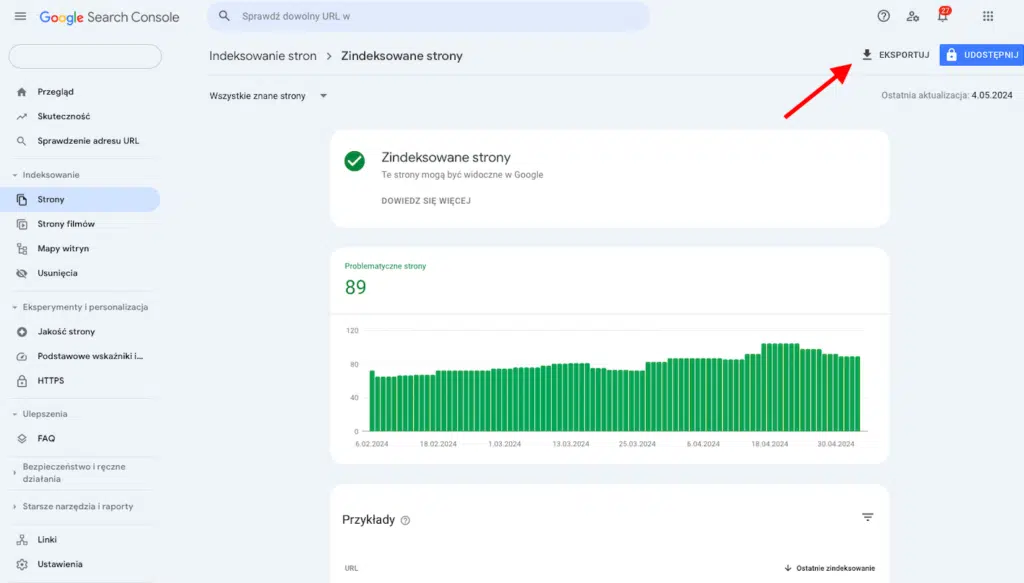
Blokowanie podstron w pliku robots.txt
Plik robots.txt to plik tekstowy znajdujący się w głównym katalogu witryny, mający na celu informowanie robotów wyszukiwarek, do których zasobów mogą uzyskać wgląd w ramach witryny, a do których nie chcesz, aby miały dostęp. W tym pliku umieszcza się również link do pliku z mapą witryny: sitemap.xml lub sitemap.txt.
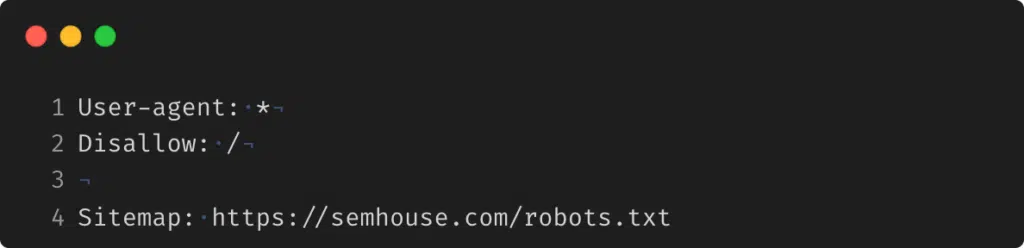
Przykładowy plik robots.txt, w którym zezwala się na dostęp do zawartości całej strony, prezentuje się następująco:
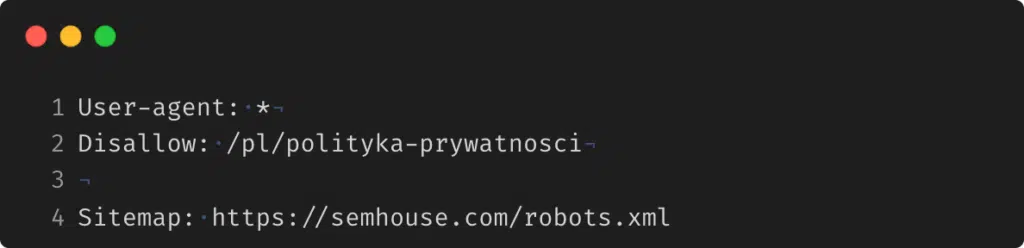
Jeżeli natomiast chcesz ograniczyć indeksowanie podstrony z polityką prywatności, plik robots.txt powinien wyglądać tak jak poniżej:
Warto zaznaczyć, że zgodnie z dokumentacją Google Search Central plik ten powinien być wykorzystywany w celu zmniejszenia ruchu robotów indeksujących na stronie, a nie jako mechanizm służący do ukrywania witryn przed Google. Warte zaznaczenia jest również, że strony lub katalogi wykluczone w pliku robots.txt mogą być nadal indeksowane, jeżeli prowadzą do nich linki z innych stron.
Adres kanoniczny – dlaczego jest ważny dla indeksacji stron?
Adres kanoniczny (ang. canonical) jest wyrażany za pomocą meta tagu umieszczonego w sekcji head strony internetowej:

lub w nagłówku odpowiedzi HTTP:

Zaprezentowane adresy kanoniczne odgrywają istotną rolę w procesie indeksacji, informując roboty wyszukiwarek internetowych o preferowanej wersji strony, dzięki czemu można uniknąć problemów związanych z duplikacją treści. Dodanie adresu kanonicznego w źródle strony ma na celu precyzyjne określenie, która wersja strony powinna być uwzględniona w wynikach wyszukiwania w przypadku zaistnienia kilku stron z podobną lub taką samą zawartością.
Rola adresów kanonicznych jest szczególnie widoczna w kontekście wcześniej wspomnianych sklepów internetowych, gdzie listy produktów wyposażone w funkcje sortowania, filtrowania i paginacji mogą generować wiele wariantów adresów URL dla tych samych treści.
Parametry w linkach: rel nofollow. Jak zatrzymać przekazywanie mocy linków?
Wspomniany we wstępie tag nofollow towarzyszy nam już prawie 20 lat – został wprowadzony przez Google w celu walki ze spamem w komentarzach i stał się rekomendowaną metodą oznaczania linków reklamowych ze względu na ograniczenie przekazania mocy.
W kontekście linkowania wewnętrznego i wpływu na wykorzystanie przez witrynę crawl budgetu oznaczanie linków atrybutem nofollow może być przydatne, aby nie marnować przydzielonych nam zasobów, szczególnie w kontekście linkowania podstron oznaczonych dyrektywą noindex oraz witryn, które wskazują wersje kanoniczne, a także tych, które zostały wykluczone w pliku robots.txt.
Powyżej przedstawiona argumentacja znajduje swoje potwierdzenie u jednego z najbardziej znanych i cenionych pracowników Google Johna Muellera, który na Twitterze w odpowiedzi na pytanie jednego z użytkowników napisał:
If they say “nofollow burns crawl budget” they don’t know what they’re talking about. Ignore them 🙂
Co w wolnym tłumaczeniu oznacza: „Jeśli ktoś twierdzi, że nofollow i tak przepala budżet crawlowania, najwyraźniej nie wie, o czym mówi. Zignoruj go”. Ta wypowiedź Muellera jednoznacznie zamyka temat, potwierdzając, że linki z parametrem nofollow umieszczone na stronie, ograniczając wykorzystanie przydzielonych zasobów, pozytywnie wpływają na zarządzanie crawl budgetem.
Jak blokować indeksowanie stron meta tagiem noindex?
Stosowanie dyrektywy noindex umożliwia kontrolę nad tym, które strony powinny zostać zaindeksowane przez wyszukiwarki, a które wykluczone z indeksu, a co za tym idzie – nad wykorzystaniem przyznanego stronie budżetu crawlowania. Meta tag noindex może być umieszczony w sekcji head strony internetowej lub przekazany za pomocą nagłówka odpowiedzi HTTP. Jest rozwiązaniem rekomendowanym przez Google, zapewniającym bardziej przewidywalne rezultaty niż blokowanie indeksacji witryny za pomocą dyrektywy w pliku robots.txt.
Umieszczenie meta tagu noindex w sekcji head strony internetowej jest stosunkowo prostym zabiegiem – po implementacji wygląda tak:

Istnieje również meta tag dedykowany robotom wyszukiwarki Google:

Zarówno pierwszy, jak i drugi sposób skutecznie blokują indeksację strony opatrzonej tym tagiem, jeżeli jednak zależy Ci na wykluczeniu strony we wszystkich znanych wyszukiwarkach, szczególnie zalecane jest użycie pierwszej dyrektywy.
Alternatywnie możliwe jest blokowanie indeksacji stron za pomocą nagłówka odpowiedzi HTTP, a wybór tej metody przeważa szczególnie w przypadku bardzo dużych projektów ze względu na łatwiejsze zarządzanie.
Przesyłanie informacji za pomocą tej metody jest bardziej zaawansowaną procedurą, która wymaga konfiguracji na poziomie serwera. W odpowiedzi HTTP serwera ustawia się wówczas nagłówek X-Robots-Tag z wartością noindex.
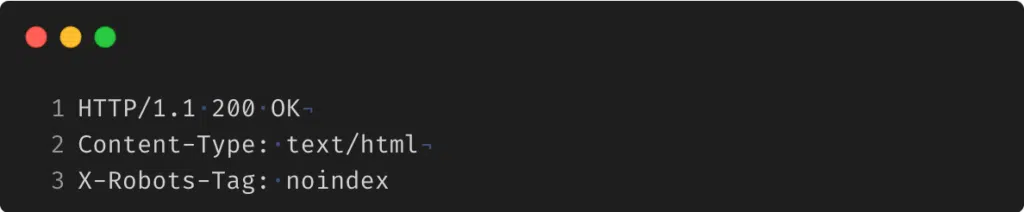
Przykładowy nagłówek odpowiedzi HTTP z dyrektywą noindex prezentuje się następująco:
Szczegółowe informacje na temat blokowania indeksowania przez wyszukiwarki za pomocą tagu noindex znajdziesz w oficjalnych wskazówkach Google: https://developers.google.com/search/docs/crawling-indexing/block-indexing?hl=pl.
Powiadomienia w Google Search Console i dobre praktyki rozwiązywania problemów z indeksowaniem
Osoby posiadające witrynę dodaną do usługi Google Search Console z pewnością niejednokrotnie spotkały się z sytuacją, w której otrzymały powiadomienie od Google o błędach indeksowania strony internetowej. Nie zawsze jednak łatwo zrozumieć, co taki komunikat oznacza. Poniżej przedstawiamy najczęściej występujące komunikaty dotyczące indeksowania stron wraz z wyjaśnieniem oraz wskazówkami, jak rozwiązać problem.
Pierwszym często pojawiającym się komunikatem jest informacja: Strona zindeksowana, ale zablokowana przez plik robots.txt. Właściciel witryny internetowej dowiaduje się w ten sposób, że pomimo zablokowania strony internetowej w pliku robots.txt została ona jednak zaindeksowana przez Google. Może to wynikać z faktu, że Googlebot znalazł link referujący do strony, która została opatrzona dyrektywą disallow. Aby uniknąć indeksowania takiej strony, należy dodać dyrektywę noindex do nagłówka HTTP lub sekcji head.
Kolejnym często występującym błędem jest Nie znaleziono (404). Błąd 404 oznacza, że roboty indeksujące nie mogły odnaleźć żądanej zawartości pod określonym adresem URL na Twojej stronie internetowej. W praktyce, gdy użytkownik lub robot wyszukiwarki próbuje odwiedzić stronę, która nie istnieje lub została usunięta, serwer zwraca kod odpowiedzi HTTP 404 Not Found. Jest to sygnał informujący przeglądarkę lub roboty indeksujące, że zawartość pod wskazanym adresem nie jest dostępna. Rozwiązaniem tego błędu jest naprawa linków na stronie lub skasowanie linków do zasobu, który nie jest już dostępny.
Trzeci często spotykany komunikat, który można napotkać w Google Search Console, to: Strona wykluczona za pomocą tagu noindex. Pojawienie się tego błędu stanowi informację, że roboty indeksujące witrynę natrafiły na stronę, na której zastosowano tag noindex, co uniemożliwia uwzględnienie jej w indeksie Google. Jeśli jest to zamierzone działanie, nie wymaga to Twojego zaangażowania. W przeciwnym razie warto sprawdzić, czy taki tag nie został umieszczony na stronie przypadkowo.
Kolejnym, nieco tajemniczym powiadomieniem jest komunikat: Strona zeskanowana, ale jeszcze nie zindeksowana. Pojawienie się tego błędu oznacza, że roboty indeksujące odwiedziły Twoją stronę internetową, ale nie została ona uwzględniona w indeksie Google. Może to być spowodowane błędami na stronie, niską jakością treści lub słabym linkowaniem wewnętrznym. Ważne jest zdiagnozowanie strony pod kątem błędów. Pomocna może być również optymalizacja treści oraz wewnętrzne linkowanie niezaindeksowanej strony.
Innym komunikatem, z którym możesz się spotkać, jest informacja, że wystąpił duplikat, a wyszukiwarka Google wybrała inną stronę kanoniczną niż użytkownik. Innymi słowy, mimo wskazania przez Ciebie strony kanonicznej, Google wybrał inną stronę, uznając ją za lepiej odpowiadającą intencjom odbiorców. Warto sprawdzić, jaki adres został wybrany przez Google i zweryfikować jego trafność. W przypadku strony nieodpowiadającej oczekiwaniom warto zoptymalizować treść pod kątem słów kluczowych i zgłosić poprawkę w Google Search Console.
Ostatnim najczęściej spotykanym błędem zgłaszanym przez GSC jest ten związany z duplikatem oraz brakiem oznaczenia strony kanonicznej. Komunikat wskazuje, że robot indeksujący wykrył w Twojej witrynie duplikat strony, któremu nie został przypisany adres kanoniczny, a Google samodzielnie wybrał lepiej odpowiadający adres URL. W takiej sytuacji warto szczegółowo przeanalizować błąd, zwracając uwagę na adres kanoniczny zaproponowany przez Google. Jeśli Ci on nie odpowiada, należy wdrożyć odpowiednie adresy kanoniczne oraz zgłosić poprawkę w Google Search Console.
Większość problemów związanych z indeksowaniem stron może być stosunkowo łatwo rozwiązana i nie wymaga zaangażowania dużej ilości czasu ani środków. Drobne korekty przynoszą niekiedy znaczące korzyści dla pozycjonowania witryny w wynikach wyszukiwania, a monitorowanie komunikatów o błędach otrzymywanych od Google Search Console może znacząco wpłynąć na efektywność działań SEO, umożliwiając szybką identyfikację i naprawę problemów.
Jak widać, zarządzanie crawl budgetem bywa procesem złożonym, lecz bardzo istotnym, zwłaszcza w przypadku większych aplikacji internetowych, gdzie zarządzanie zawartością i strukturą witryny może być bardziej skomplikowane. Właściwa implementacja adresów kanonicznych, kontrolowanie przepływu mocy oraz wykluczenie niektórych stron powinny stanowić kluczowe punkty analizy technicznej serwisu w ramach profesjonalnego audytu SEO.
